Site search
Veel sites en webshops hebben een zoekveld/zoekfunctionaliteit. Deze helpt een klant bij het vinden van specifieke producten, categorieën of pagina's. Door het automatisch vertalen van de producten komt het vaak voor dat de zoekfunctionaliteit niet meer werkt, of een verkeerde product database gebruikt. Clonable biedt 2 oplossingen voor dit probleem.
Vertaalde integratie van huidige zoekfunctie
Vaak maken webshops/websites gebruik van een externe zoekfunctie, denk hierbij aan Doofinder, Sooqr of een custom integratie. Het is bij deze systemen mogelijk om een extra zoekfunctie aan te maken voor de clone. Wanneer je al een XML product feed hebt voor je originele taal, dan heb je de mogelijkheid om deze tegen betaling te vertalen via Clonable. (Deze feed kan ook gebruikt worden voor Google Shopping, of andere marketplaces.)
Wanneer je een vertaalde product feed hebt, kun je deze instellen bij de zoekfunctie tool naar keuze, en dan kan je aan de kant van Clonable vaak het ID van de originele zoekfunctie vervangen met die van de vertaalde versie.
Heb je hulp nodig bij het instellen van een vertaalde zoekfunctie? Neem dan gerust contact met ons op.
📄️ XML feeds
Hier leest u meer over het vertalen van de XML feeds van uw geclonede website.
📄️ Substitution rules
Hier leest u hoe u onze substitution rules regels voor het wijzigen van HTMl kunt maken.
Clonable site search
In sommige gevallen is het niet mogelijk om een extra zoekfunctie, of custom zoekveld toe te voegen aan de pagina, hiervoor biedt Clonable een eigen zoekfunctie. Deze kun je dan integreren op de clone, zodat er nog steeds gezocht kan worden op de clone.
De site search werkt simpelweg door zelf een search index te maken van de vertaalde pagina's van de clone. Het indexeren van de search zal starten wanneer je de site search aanzet (zie de rode "Site search: OFF" knop rechtsboven in de pagina).
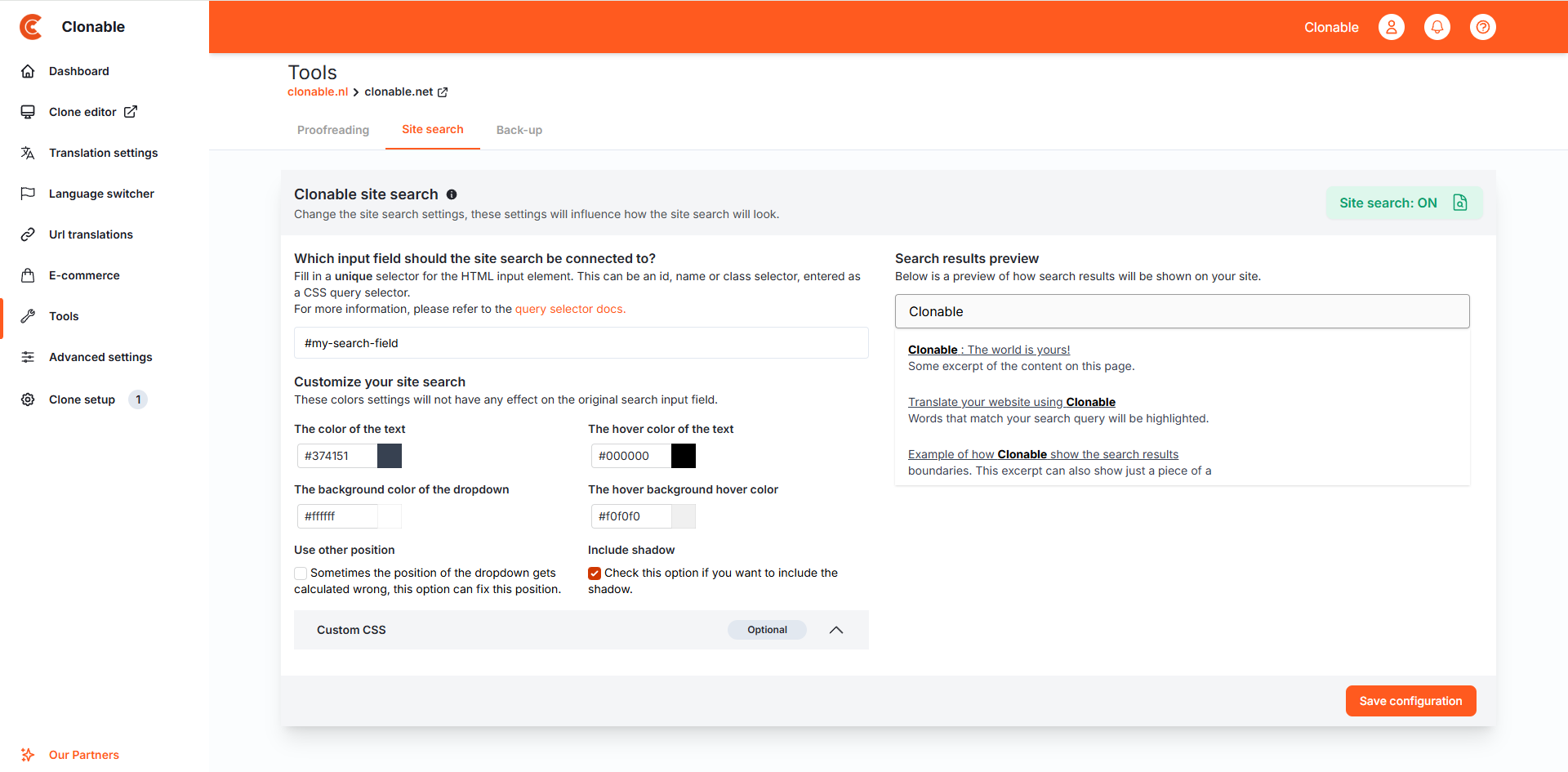
Hoe krijg ik hem op de site
Met de settings op de site search pagina kun je configureren hoe het zoeken eruit ziet, en waar de functie op de pagina terecht zal komen. De locatie van de zoekfunctie wordt bepaald door de "Which input field should the site search be connnected to?" instelling, hier wordt vereist om een query selector in te voeren voor het zoekveld van de zoekfunctie. We raden aan om hier een unieke CSS selector te gebruiken, dit wordt vaak aan de hand van een HTML id gedaan.
Wanneer je de configuratie van de zoekfunctie opslaat EN de site search aanstaat, wordt de configuratie automatisch geïnjecteerd in de HTML body van de clone. Deze is te vinden bij de general settings van de clone. Dat ziet er dan als volgt uit:
<!-- DO NOT MODIFY - START SEARCH ENGINE -->
<script>const clonableSEC = {"inputSelector":"#my-search-field","language":"en","cloneDomain":"clonable.net","textColor":"#374151","textHoverColor":"#000000","backgroundColor":"#ffffff","backgroundHoverColor":"#f0f0f0","includeShadow":"1","useAbsoluteInputPosition":false,"customCss":"","maximumDropDownHeight":400,"searchDebounceTime":300,"maximumResultStringLength":125}</script>
<script src="https://modules.clonable.net/search-engine/js/init.js?v=1.0.0"></script>
<!-- DO NOT MODIFY - END SEARCH ENGINE -->
Het verder nog mogelijk om de kleuren en CSS aan te passen zodat het beter binnen de huisstijl van de website past.
Hoe werkt de zoekfunctie?
Op de achtergrond maakt Clonable een custom search index aan voor de clone, deze search index is opgebouwd uit de volgende attributen/elementen:
- Meta title
- Meta description
- H1
- H2
- Gehele content
Clonable heeft een prioriteit van deze attributen, zo worden de H1 en de meta title zwaarder meegerekend voor het resultaat van de search output dan de html content van de pagina. Dit zorgt ervoor dat je de meest ideale content terugkrijgt aan de hand van de invoer.
Op de achtergrond houdt de zoekfunctie er ook nog rekening mee wanneer en typfouten worden gemaakt.
Indexeren van pagina's
Voordat er pagina's geïndexeerd zullen worden door Clonable, is het van belang dat je clone voldoet aan de volgende eisen.
- Clone moet indexeerbaar zijn.
- Robots.txt moet het toestaan om te crawlen.
Clonable neemt de standaard regelset van GoogleBot over. Dus zolang een GoogleBot kan crawlen zullen de pagina's ook geïndexeerd worden door de Site search. Wanneer een pagina geïndexeerd is, zal het een week duren voordat die weer opnieuw wordt gecontroleerd.
Clonable heeft een rate limit geïmplementeerd voor het indexeren van de pagina's van de clone. Er kunnen maximaal 2 pagina's per minuut worden geïndexeerd door de Clonable site search. Dus wanneer je 1.000 pagina's moet indexeren, zou de totale tijd als volgt zijn: 1.000 pagina's / 2 pagina's/minuut = 500 minuten = ongeveer 8,5 uur. Als je dus 's avonds een crawler zou aanzette, zullen gedurende de nacht alle pagina's geïndexeerd worden.