Site search
Many websites and webshops have a search field/search functionality. This helps the customer find specific products/categories or pages. Due to the automatic translation of products, it often happens that the search functionality stops working, or uses the wrong product database. Clonable offers 2 solutions to these problems.
Translated integration of current search function
It often happens that a webshop or website uses an external search function, for example Doofinder, Sooqr or a custom integration. With these systems, it is possible to create an extra search function for the clone. If you already have an XML product feed for your original language, you have the option of translating it via Clonable for a fee. (*This feed can also be used for Google Shopping, or other marketplaces.)
After you create a translated product feed, you can set it up with the search tool of your choice, and then on Clonable's side, you can replace the ID of the original search tool with that of the translated version.
Need help setting up a translated search function? If so, feel free to contact us.
📄️ XML feeds
Here you can read everything about how to translate the XML feeds of your cloned webshop.
📄️ Substitution rules
Here you can read everything regarding using our substitution rules to make changes to HTML.
Clonable site search
In some cases it is not possible to add an additional search function, or custom search field to the page. For this Clonable offers its own search function. You can then integrate this on the clone, so that you can still use a search function on the clone.
The site search works simply by creating its own search index from the translated pages of the clone. Indexing will start when you turn on site search (see the red "Site search: OFF" button at the top right of the page).
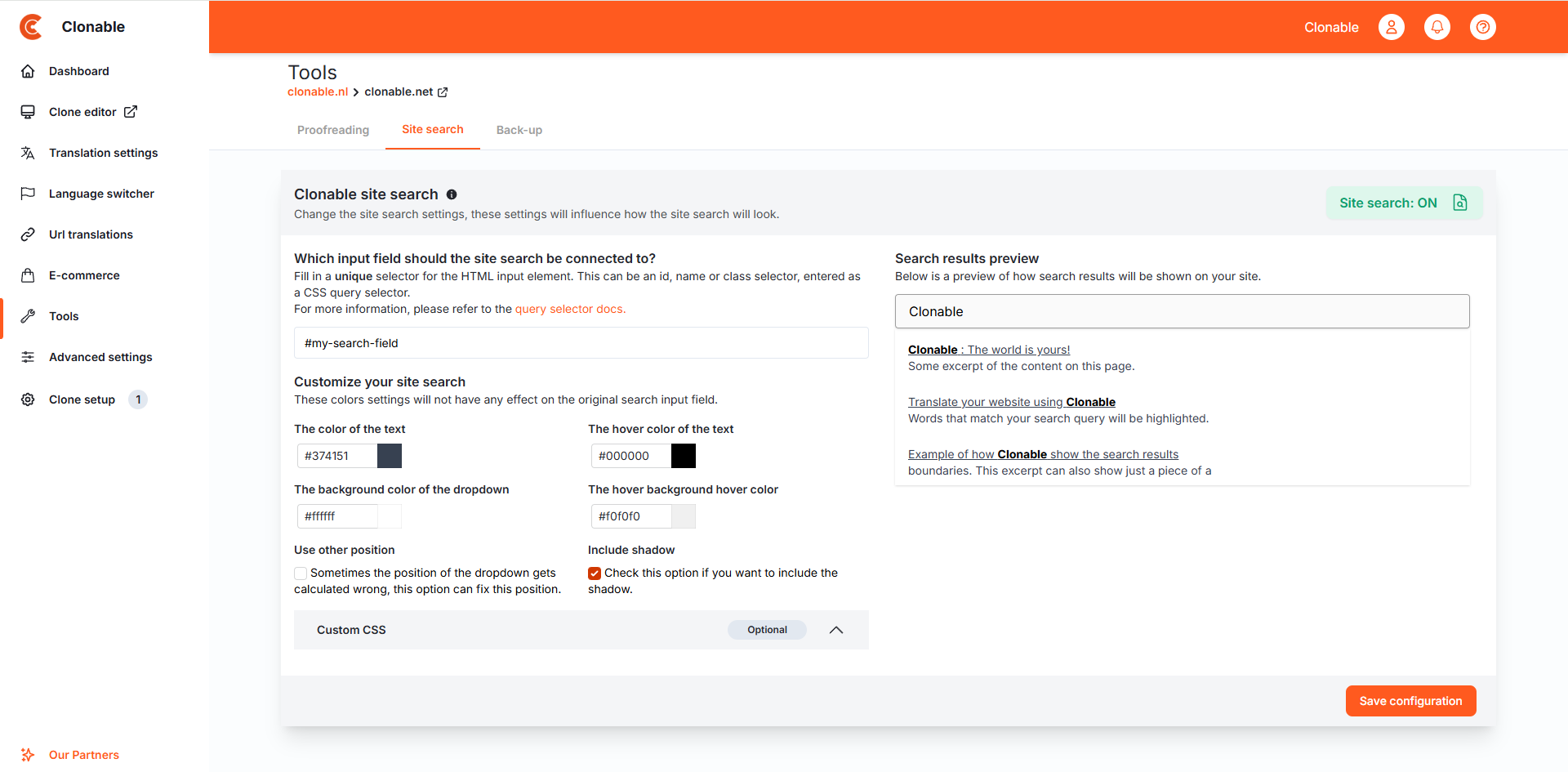
How do I get it on the site
The settings on the site search page allow you to configure what the search looks like and where the function will land on the page. The location of the search function is determined by the "Which input field should the site search be connnected to?" setting, here it is required to enter a query selector for the search field of the search function. We recommend using a unique CSS selector here, this is often done using an HTML id.
When you save the configuration of the search function AND the site search is on, the configuration is automatically injected into the HTML body of the clone. It can be found in the clone's general settings. It then looks like this:
<!-- DO NOT MODIFY - START SEARCH ENGINE -->
<script>const clonableSEC = {"inputSelector":"#my-search-field","language":"en","cloneDomain":"clonable.net","textColor":"#374151","textHoverColor":"#000000","backgroundColor":"#ffffff","backgroundHoverColor":"#f0f0f0","includeShadow":"1","useAbsoluteInputPosition":false,"customCss":"","maximumDropDownHeight":400,"searchDebounceTime":300,"maximumResultStringLength":125}</script>
<script src="https://modules.clonable.net/search-engine/js/init.js?v=1.0.0"></script>
<!-- DO NOT MODIFY - END SEARCH ENGINE -->
It is also possible to customise the colours and CSS to better fit within the clone's house style.
How does the search function work?
In the background, Clonable creates a custom search index for the clone, this search index is made up of the following attributes/elements:
- Meta title
- Meta description
- H1
- H2
- Entire content
Clonable also prioritises these attributes, so the H1 and the meta title count more for the result of the search output than the html content of the page does. This ensures that you get back the most ideal content based on the input.
In the background, the search function also takes into account when typos are made.
Indexing pages
Before any pages will be indexed by Clonable, it is important that your clone meets the following requirements.
- Clone must be indexable.
- Robots.txt must allow to crawl.
Clonable adopts GoogleBot's default rule set. So as long as a GoogleBot can crawl, pages will also be able to be indexed by Site search. Once a page is indexed, it will take a week before it is checked again.
Clonable has implemented a rate limit for indexing clone pages. A maximum of 2 pages per minute can be indexed by the Clonable site search. So when you need to index 1,000 pages, the total time would be as follows: 1,000 pages / 2 pages/minute = 500 minutes = about 8.5 hours. So if you were to turn on a crawler in the evening, all pages will be indexed during the night.